From Scanned PDF to Structured Database: Digitizing 19th-Century US Legal Codes
- Shyrley P.

- Apr 5
- 5 min read
What automated OCR misses when the source material is 150 years old, and how we handled it.
A legal history researcher sent us four PDFs. Each contained a different US state's civil code from the 1870s: California, North Dakota, South Dakota, and Montana. The goal was a structured Excel database where every section of law had its own row. Section number and full text cleanly separated, consistently formatted, and ready for database import and comparative analysis.

Simple enough on paper. Here is what we were actually working with.
At a glance
Documents
4 state legal codes, 1870s
Deliverable
Structured Excel database, importable
Client
Academic legal historian, US university
Approach
OCR + systematic manual
verification
The Project
The researcher was building a comparative database of 19th-century American civil law. For each state, every section of the legal code needed its own row — section number and full section text cleanly separated, consistently formatted, and ready for database import and comparative analysis.
What made this more than a standard conversion task was the variation between the four documents. Each state's legislature had organized and formatted its code differently. Each had its own conventions for marginal notes, section references, footnotes, and numbering systems. Understanding those conventions before touching the data was essential — an error in the extraction logic would propagate across hundreds of rows rather than appearing as a single isolated mistake.
The Source Material
All four PDFs had been digitized from physical copies of the original printed codes. Scan quality varied between documents and sometimes between pages within the same document. Older typefaces, inconsistent inking, and the natural deterioration of 150-year-old paper all contributed to source material that looked readable to the human eye but presented real challenges for automated character recognition.
None of the four documents were identical in structure. Before any data was extracted, each document needed to be read and understood on its own terms.
Document by Document: What We Found
Each state presented its own structural challenge. Here is what we encountered in each one.
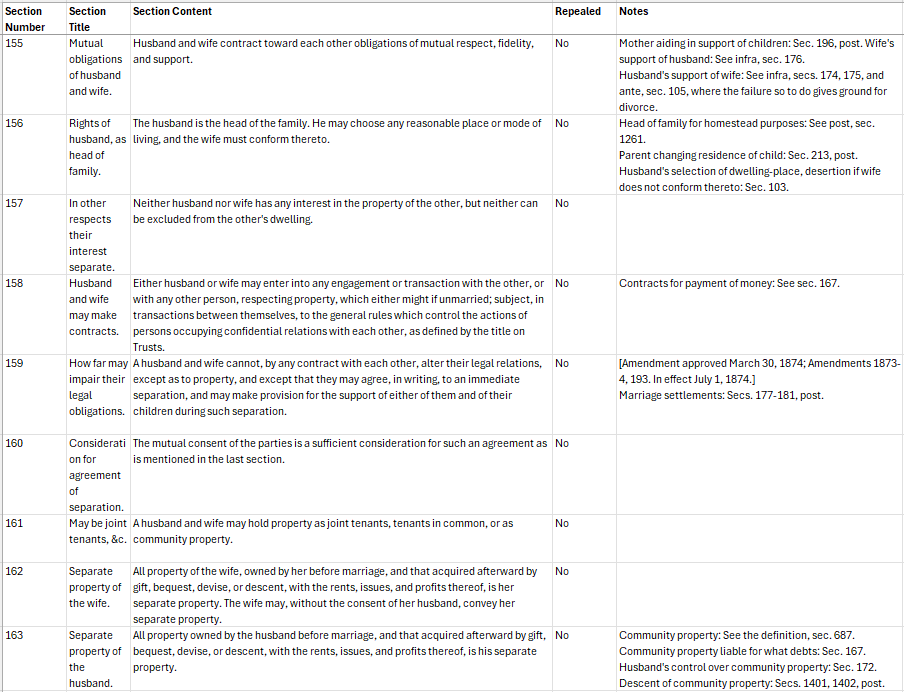
California · 1872
Repealed sections and layered footnotes
Sections had been formally repealed since original publication. Each needed its own row marked "repealed" — a missing row is itself a data point for a legal historian. Footnotes with amendment history required a dedicated column separate from the main section text.
North Dakota
Two parallel numbering systems
Current section numbers ran alongside older civil code numbers printed in the margin. Both were in active use by researchers. Every row needed both correctly linked — a single misalignment would cascade into errors for anyone cross-referencing the material.
South Dakota
Marginal annotations bleeding into body text
Section titles and source citations ran alongside the main text in the margins. OCR tools don't always respect visual layout — marginal content frequently bleeds into adjacent columns. Correct separation required reading the original, not the automated output.
Montana
Structurally clean — but not error-free
Montana's code was the most straightforward of the four. Consistent formatting, no parallel numbering, no complex footnote apparatus. After the other three states, this was a relief. That said, the same OCR character recognition issues required the same careful verification approach.
The core challenge
OCR gets you close. It doesn't get you there.
Modern OCR performs well on clean, consistently formatted, recently printed text. It has been trained on enormous volumes of contemporary documents. Historical documents break most of those assumptions.
Typefaces from the 1870s don't look like contemporary fonts. Ink bleed and paper yellowing alter character shapes in ways that confuse pattern recognition. Page margins are inconsistent. Legal shorthand and typographic conventions of the period have no modern equivalent in the training data.
The result is output that looks plausible at a glance but contains a consistent background noise of small errors. A "1" that should be a lowercase "l." A section number where a stray footnote marker has been incorporated into the digit string, turning "39" into "339."
In a database used for comparative legal analysis, any of these errors can corrupt the results of a query, break a cross-reference, or cause a section to be miscounted. The only reliable way to catch them is systematic comparison between OCR output and the original source. That is a human task, not an automated one.
Our Approach
We used a hybrid process combining automated extraction with structured manual verification. Neither alone would have been sufficient.
1 Automated extraction
We ran each document through OCR to produce an initial text output. This gave us a working draft to build from rather than starting from a blank spreadsheet, and handled straightforward sections reliably enough to save significant time on the cleaner portions of each document.
2 Structural mapping
Before any data went into the spreadsheet, we read enough of each original document to understand its conventions fully. Where do footnotes appear? How are section breaks marked? What does a repealed section look like versus an amended one? This mapping step informed every subsequent decision about ambiguous cases.
3 Column definition
For each state we defined the column structure before populating any rows, in discussion with the researcher. Getting this right at the start meant the output would be consistent and importable without restructuring later.
4 Manual verification
Every row was verified against the source document. Not spot-checked — verified. For sections flagged as potentially problematic during the automated pass, we compared character by character. Footnote markers were traced back to their corresponding notes and matched. Parallel numbers were cross-checked for alignment.
5 Ambiguity documentation
When something in the source was genuinely unclear — a damaged section, an ambiguous footnote reference, a marginal number in a different hand — we documented it rather than guessing. The researcher received a separate notes file flagging every judgment call and why, so they could review and decide independently.
What We Delivered
Four state-specific Excel files, each structured according to the column definitions agreed on at the outset.
Every section accounted for, including repealed sections in California marked for manual follow-up
Both numbering systems correctly linked in North Dakota, with no misalignments
Marginal annotations cleanly separated into dedicated columns in South Dakota
A separate notes file documenting every ambiguous case and the judgment calls made
Files formatted for direct database import without restructuring
"My highest recommendation — great attention to detail, clear communications, and goes above and beyond." Legal history researcher, US university
What This Kind of Project Requires
Historical legal transcription is not a data entry job in the conventional sense. It requires enough familiarity with historical document conventions to recognize when something looks wrong, enough patience to verify output systematically rather than sampling, and enough communication discipline to flag uncertainty rather than resolve it unilaterally.
It also requires a clear process agreed on before work begins. The column definitions, the handling rules for edge cases, the format of the final output — all of these need to be settled at the start, because changing them halfway through a multi-hundred-row database is expensive in time and introduces new opportunities for error.
If you are working with historical legal documents, archival records, or any scanned source material from before the era of digital publishing, we are glad to talk through your project before you commit to anything. We are happy to look at a sample file, discuss the scope, and give you a realistic picture of what the work involves.
Get in touch Working with difficult historical documents? We specialize in the work that comes after OCR: verification, correction, structuring, and formatting for research use. Send us a sample and we will tell you exactly what is involved. |


